
MiniMax-Music-2.0 AI音乐大模型API使用文档
使用music-2.0模型,输入歌词和歌曲描述,进行歌曲生成。
请求地址
https://www.dmxapi.cn/v1/responses模型列表
music-2.0
参数解释
lyrics参数解释。 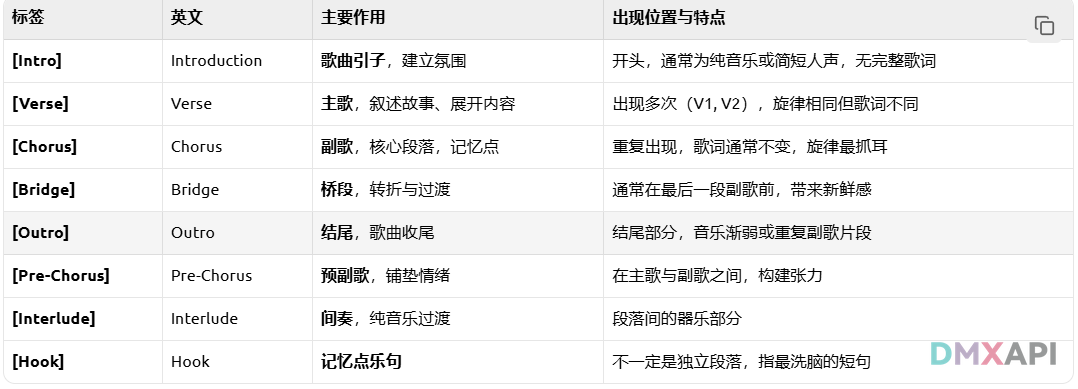
示例代码
python
"""
================================================================================
DMXAPI 音乐生成脚本
================================================================================
功能说明:
本脚本通过 DMXAPI 平台调用音乐生成模型(music-2.0)生成音乐。
支持自定义歌词、音乐风格描述和音频输出设置。
使用流程:
1. 配置 API 密钥和音乐参数
2. 运行脚本生成音乐
3. 音频文件将保存为 output.mp3
依赖库:
- requests: HTTP 请求库
- json: JSON 处理库
================================================================================
"""
import requests
import json
# ============================================================================
# 配置部分 - API 连接信息
# ============================================================================
# DMXAPI 的 URL 地址
url = "https://www.dmxapi.cn/v1/responses"
# API 密钥 - 用于身份验证和访问控制
api_key = "sk-***************************************" # ⚠️ 请替换为你的API密钥
# ============================================================================
# 请求头配置 - 设置内容类型和授权信息
# ============================================================================
headers = {
"Content-Type": "application/json", # 指定请求体为 JSON 格式
"Authorization": f"{api_key}", # token 认证方式
}
# ============================================================================
# 请求参数配置 - 音乐生成参数
# ============================================================================
data = {
# -------------------- 基础配置 --------------------
"model": "music-2.0", # 音乐生成模型版本
# 音乐描述
# - 长度限制: 10-2000 个字符
"input": "这是一首充满自信、大胆果决力量的当代 R&B/Pop 歌曲,并融入了鲜明的 Trap 元素。歌曲由明亮、清澈且灵活的女声演绎,其经过精心处理的现代音色极具辨识度,歌手自信的节奏性唱腔,结合极具风格化的 Auto-Tune 修音效果,构成了其核心听感。大量层次丰富的和声、伴唱与即兴点缀,通过主旋律的同度和声堆叠,营造出饱满而充满能量的听觉体验,并配以恰到好处的混响效果来提升空间感。在 80 BPM 的节奏下,编曲以标志性的 808 贝斯和鼓点作为驱动,搭配复杂的碎拍与清脆的拍手声,并由氛围合成器铺垫出广阔的背景,同时点缀着过渡性的音效,非常适合在俱乐部、派对、驾车或健身时收听,为你的自信时刻注入能量。",
# 歌词内容
# - 长度限制: 10-3000 个字符
# - 每行歌词用换行符分隔
# - 可使用标签: [Intro], [Verse], [Chorus], [Bridge], [Outro]
"lyrics": ("[intro]\n"
"D.M.X., 取自AI模型\n"
"dmxapi, 聚合智能\n"
"智能中文网, 为你开启\n"
"AI 应用的大门\n"
"\n"
"[verse]\n"
"三百多模型汇聚一堂\n"
"文生文, 文生图, 文生视频与音频\n"
"多模态的世界, 深度学习的力量\n"
"自然语言处理, 图像识别在掌中\n"
"\n"
"[chorus]\n"
"dmxapi, 智能的钥匙\n"
"一个 Key 打开所有模型\n"
"文生图, 文生音乐, 文生视频全都有\n"
"全球 API 直连, 本地计价\n"
"\n"
"[verse]\n"
"注册就是满级, 无限并发\n"
"没有 RPM 限制, 没有 TPM 烦恼\n"
"企业集群服务器, 支持公对公\n"
"企业服务, 正规流程\n"
"\n"
"[bridge]\n"
"直接与原厂合作, 集中采购\n"
"去掉中间环节, 价格更优\n"
"高性价比方案, 助力创新\n"
"节省预算, 提升效果\n"
"\n"
"[chorus]\n"
"dmxapi, 智能的钥匙\n"
"一个 Key 打开所有模型\n"
"文生图, 文生音乐, 文生视频全都有\n"
"全球 API 直连, 本地计价\n"
"\n"
"[outro]\n"
"dmxapi\n"
"开启你的\n"
"智能创作之旅"),
# -------------------- 音频设置 --------------------
"audio_setting": {
"sample_rate": 44100, # 采样率 (可选: 16000, 24000, 32000, 44100)
"bitrate": 256000, # 比特率 (可选: 32000, 64000, 128000, 256000)
"format": "mp3" # 编码格式 (可选: mp3, wav, pcm)
},
# -------------------- 流式传输参数 --------------------
# stream: 是否使用流式传输,默认 false
"stream": False,
# output_format: 音频返回格式
# - 可选值: url, hex (默认 hex)
# - stream=true 时仅支持 hex
# - url 有效期 24 小时,请及时下载
"output_format": "hex",
# aigc_watermark: 是否在音频末尾添加水印
# - 默认 false
# - 仅在 stream=false 时生效
"aigc_watermark": False,
}
# ============================================================================
# 发送请求并处理响应
# ============================================================================
print("🎵 开始生成音乐...")
print(f"📝 音乐风格: {data['input'][:50]}...")
print(f"🎤 歌词长度: {len(data['lyrics'])} 字符")
print("-" * 60)
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
result = response.json()
print("✅ API 响应成功")
# 提取音频数据(兼容多种响应格式)
audio_data = None
if "output" in result and isinstance(result["output"], list):
for item in result["output"]:
for content in item.get("content", []):
if "audio" in content:
audio_data = content["audio"]
break
audio_data = audio_data or result.get("data", {}).get("audio") or result.get("audio")
if audio_data:
# 下载或解码音频
if audio_data.startswith("http"):
audio_bytes = requests.get(audio_data).content
else:
audio_bytes = bytes.fromhex(audio_data)
with open("output.mp3", "wb") as f:
f.write(audio_bytes)
print(f"🎉 音乐生成成功!已保存为 output.mp3")
print(f"📊 文件大小: {len(audio_bytes) / 1024 / 1024:.2f} MB")
elif "error" in result:
print(f"❌ API 错误: {result['error'].get('message', '未知错误')}")
else:
print("⚠️ 意外的响应格式:")
print(json.dumps(result, indent=2, ensure_ascii=False))
except requests.exceptions.RequestException as e:
print(f"❌ 请求错误: {e}")
except Exception as e:
print(f"❌ 错误: {e}")
print("-" * 60)
print("📌 提示: 如果生成失败,请检查 API密钥、网络连接、DMXAPI服务状态")python
"""
================================================================================
DMXAPI 音乐生成脚本 - 流式版本
================================================================================
功能说明:
本脚本通过 DMXAPI 平台调用音乐生成模型(music-2.0)生成音乐。
使用流式传输(SSE)实时接收音频数据。
支持自定义歌词、音乐风格描述和音频输出设置。
使用流程:
1. 配置 API 密钥和音乐参数
2. 运行脚本生成音乐(流式接收)
3. 音频文件将保存为 output_stream.mp3
特性:
- 流式传输,实时显示生成进度
- 支持大文件传输
- 降低内存占用
依赖库:
- requests: HTTP 请求库
- json: JSON 处理库
================================================================================
"""
import requests
import json
# ============================================================================
# 配置部分 - API 连接信息
# ============================================================================
# DMXAPI 的 URL 地址
url = "https://www.dmxapi.cn/v1/responses"
# API 密钥 - 用于身份验证和访问控制
api_key = "sk-**************************************" # ⚠️ 请替换为你的API密钥
# ============================================================================
# 请求头配置 - 设置内容类型和授权信息
# ============================================================================
headers = {
"Content-Type": "application/json", # 指定请求体为 JSON 格式
"Authorization": f"{api_key}", # token 认证方式
}
# ============================================================================
# 请求参数配置 - 音乐生成参数(流式版本)
# ============================================================================
data = {
# -------------------- 基础配置 --------------------
"model": "music-2.0", # 音乐生成模型版本
# 音乐描述
# - 长度限制: 10-2000 个字符
"input": "这是一首充满自信、大胆果决力量的当代 R&B/Pop 歌曲,并融入了鲜明的 Trap 元素。歌曲由明亮、清澈且灵活的女声演绎,其经过精心处理的现代音色极具辨识度,歌手自信的节奏性唱腔,结合极具风格化的 Auto-Tune 修音效果,构成了其核心听感。大量层次丰富的和声、伴唱与即兴点缀,通过主旋律的同度和声堆叠,营造出饱满而充满能量的听觉体验,并配以恰到好处的混响效果来提升空间感。在 80 BPM 的节奏下,编曲以标志性的 808 贝斯和鼓点作为驱动,搭配复杂的碎拍与清脆的拍手声,并由氛围合成器铺垫出广阔的背景,同时点缀着过渡性的音效,非常适合在俱乐部、派对、驾车或健身时收听,为你的自信时刻注入能量。",
# 歌词内容
# - 长度限制: 10-3000 个字符
# - 每行歌词用换行符分隔
# - 可使用标签: [Intro], [Verse], [Chorus], [Bridge], [Outro]
"lyrics": ("[intro]\n"
"D.M.X., 取自AI模型\n"
"dmxapi, 聚合智能\n"
"智能中文网, 为你开启\n"
"AI 应用的大门\n"
"\n"
"[verse]\n"
"三百多模型汇聚一堂\n"
"文生文, 文生图, 文生视频与音频\n"
"多模态的世界, 深度学习的力量\n"
"自然语言处理, 图像识别在掌中\n"
"\n"
"[chorus]\n"
"dmxapi, 智能的钥匙\n"
"一个 Key 打开所有模型\n"
"文生图, 文生音乐, 文生视频全都有\n"
"全球 API 直连, 本地计价\n"
"\n"
"[verse]\n"
"注册就是满级, 无限并发\n"
"没有 RPM 限制, 没有 TPM 烦恼\n"
"企业集群服务器, 支持公对公\n"
"企业服务, 正规流程\n"
"\n"
"[bridge]\n"
"直接与原厂合作, 集中采购\n"
"去掉中间环节, 价格更优\n"
"高性价比方案, 助力创新\n"
"节省预算, 提升效果\n"
"\n"
"[chorus]\n"
"dmxapi, 智能的钥匙\n"
"一个 Key 打开所有模型\n"
"文生图, 文生音乐, 文生视频全都有\n"
"全球 API 直连, 本地计价\n"
"\n"
"[outro]\n"
"dmxapi\n"
"开启你的\n"
"智能创作之旅"),
# -------------------- 音频设置 --------------------
"audio_setting": {
"sample_rate": 44100, # 采样率 (可选: 16000, 24000, 32000, 44100)
"bitrate": 256000, # 比特率 (可选: 32000, 64000, 128000, 256000)
"format": "mp3" # 编码格式 (可选: mp3, wav, pcm)
},
# -------------------- 流式传输参数 --------------------
# stream: 是否使用流式传输,默认 false
"stream": True,
# output_format: 音频返回格式
# - 可选值: url, hex (默认 hex)
# - stream=true 时仅支持 hex
# - url 有效期 24 小时,请及时下载
"output_format": "hex",
# aigc_watermark: 是否在音频末尾添加水印
# - 默认 false
# - 仅在 stream=false 时生效
"aigc_watermark": False,
}
# ============================================================================
# 流式响应处理函数
# ============================================================================
def parse_sse_line(line):
"""
解析SSE(Server-Sent Events)格式的行
SSE格式示例:
data: {"id":"123","audio_chunk":"hex_data"}
"""
if line.startswith("data: "):
try:
# 移除 "data: " 前缀并解析JSON
json_str = line[6:] # "data: " 长度为6
if json_str.strip() and json_str.strip() != "[DONE]":
return json.loads(json_str)
except json.JSONDecodeError as e:
print(f"⚠️ 解析行失败: {e}")
print(f" 原始行: {line}")
return None
# ============================================================================
# 发送请求并处理流式响应
# ============================================================================
print("🎵 开始生成音乐...")
print(f"📝 音乐风格: {data['input'][:50]}...")
print(f"🎤 歌词长度: {len(data['lyrics'])} 字符")
print("-" * 60)
# 用于存储音频块
audio_chunks = []
def extract_audio(data, keys=["data", "audio", "audio_data", "content", "hex", "base64"]):
"""从字典中提取音频数据"""
for key in keys:
if key in data:
return data[key]
return None
def extract_audio_from_output(output_list):
"""从 output 列表中提取音频"""
for item in output_list:
if item.get("type") == "message":
for content in item.get("content", []):
if content.get("type") == "output_audio":
return extract_audio(content)
return None
try:
response = requests.post(url, headers=headers, json=data, stream=True)
response.raise_for_status()
for line in response.iter_lines():
if not line:
continue
parsed = parse_sse_line(line.decode('utf-8').strip())
if not parsed:
continue
# 流式音频块
if "audio_chunk" in parsed:
audio_chunks.append(parsed["audio_chunk"])
# 完整音频(旧格式)
elif "audio" in parsed:
audio_chunks = [parsed["audio"]]
break
# output 格式
elif "output" in parsed:
audio = extract_audio_from_output(parsed["output"])
if audio:
audio_chunks = [audio]
if parsed.get("type") == "response.completed":
break
# response 包装格式
elif "response" in parsed:
resp = parsed["response"]
audio = extract_audio_from_output(resp.get("output", []))
if not audio:
audio = extract_audio(resp)
if audio and (not isinstance(audio, str) or len(audio) > 1000):
audio_chunks = [audio] if isinstance(audio, str) else audio
if parsed.get("type") == "response.completed":
break
# 错误处理
elif "error" in parsed:
print(f"❌ API 错误: {parsed['error'].get('message', '未知错误')}")
break
elif parsed.get("status") == "failed":
print(f"❌ 生成失败: {parsed.get('message', '未知错误')}")
break
# 保存音频
if audio_chunks:
audio_bytes = bytes.fromhex("".join(audio_chunks))
output_file = "output_stream.mp3"
with open(output_file, "wb") as f:
f.write(audio_bytes)
file_size_mb = len(audio_bytes) / 1024 / 1024
print(f"✅ 音乐生成成功!已保存为 {output_file}")
print(f"📊 文件大小: {file_size_mb:.2f} MB")
with open("music-2.0.json", "w", encoding="utf-8") as f:
json.dump({
"model": data["model"], "input": data["input"], "lyrics": data["lyrics"],
"audio_setting": data["audio_setting"], "output_file": output_file,
"file_size_bytes": len(audio_bytes), "file_size_mb": round(file_size_mb, 2)
}, f, ensure_ascii=False, indent=2)
else:
print("❌ 未接收到音频数据")
except requests.exceptions.RequestException as e:
print(f"❌ 请求错误: {e}")
except KeyboardInterrupt:
print("\n❌ 用户中断")
except Exception as e:
print(f"❌ 错误: {e}")
print("-" * 60)
print("📌 提示: 如果生成失败,请检查 API密钥、网络连接、DMXAPI服务状态")返回示例
json
🎵 开始生成音乐...
📝 音乐风格: 这是一首充满自信、大胆果决力量的当代 R&B/Pop 歌曲,并融入了鲜明的 Trap 元素。歌曲由明...
🎤 歌词长度: 429 字符
------------------------------------------------------------
✅ API 响应成功
🎉 音乐生成成功!已保存为 output.mp3
📊 文件大小: 2.49 MB
------------------------------------------------------------
📌 提示: 如果生成失败,请检查 API密钥、网络连接、DMXAPI服务状态json
🎵 开始生成音乐...
📝 音乐风格: 这是一首充满自信、大胆果决力量的当代 R&B/Pop 歌曲,并融入了鲜明的 Trap 元素。歌曲由明...
🎤 歌词长度: 429 字符
------------------------------------------------------------
✅ API 响应成功
🎉 音乐生成成功!已保存为 output_stream.mp3
📊 文件大小: 5.06 MB
------------------------------------------------------------
📌 提示: 如果生成失败,请检查 API密钥、网络连接、DMXAPI服务状态API 密钥安全
⚠️ 重要:示例代码中的 API 密钥仅供演示,请务必:
- 使用您自己的 API 密钥
- 不要将密钥硬编码在代码中
- 建议通过环境变量管理密钥
- 不要将包含真实密钥的代码提交到公开仓库
© 2025 DMXAPI music-2.0 音乐模型