
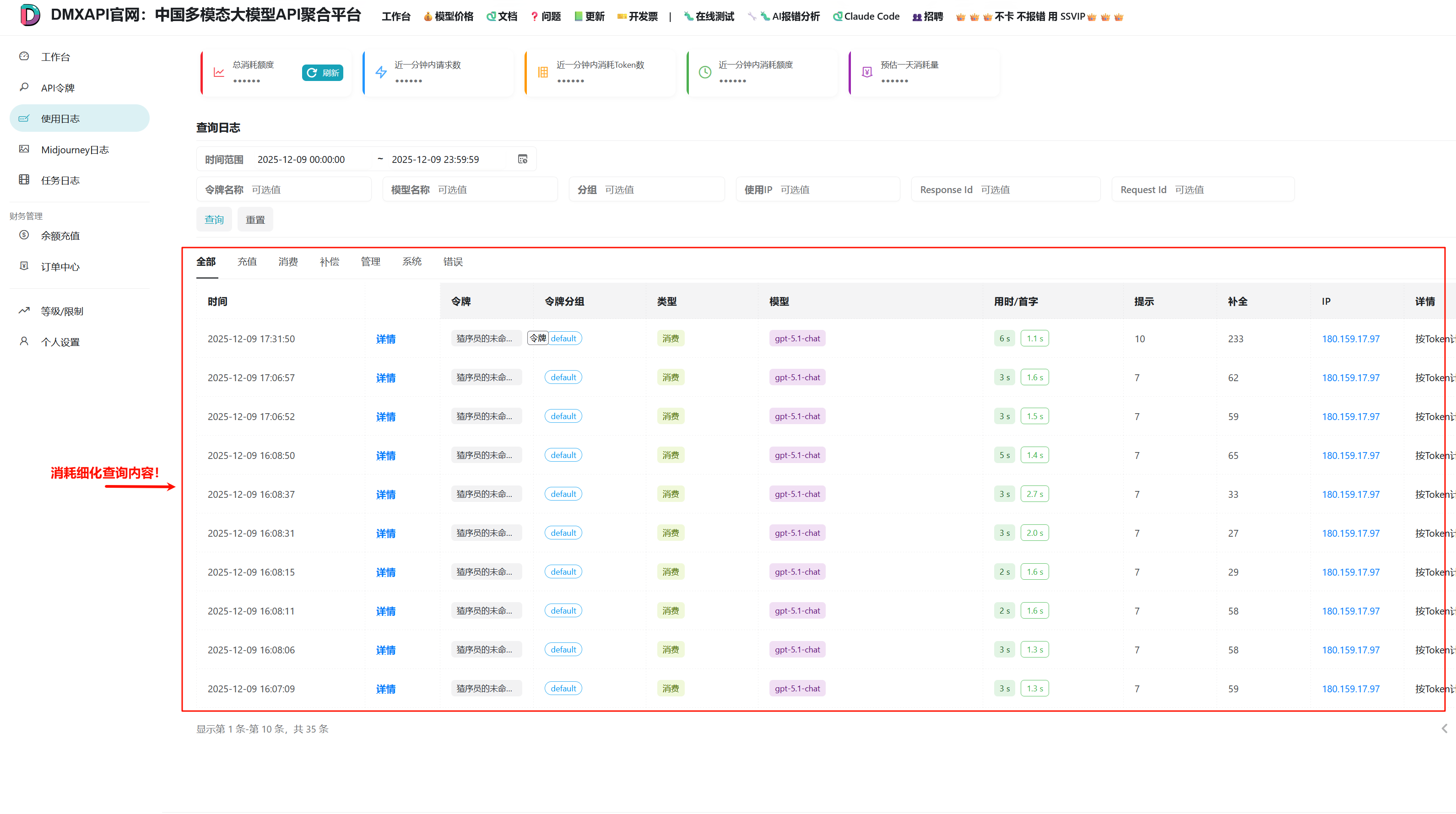
消耗细化 日志查询
总消耗查询内容在DMXAPI的位置
接口地址
https://www.dmxapi.cn/api/log/self代码示例
python
import requests
from datetime import datetime
# ===== 只需修改这里 =====
# 认证信息
SYSTEM_TOKEN = "*********" # 系统令牌,获取路径:登录DMXAPI → 工作台 → 个人设置 → 更多选项 → 系统令牌
USER_ID = "*****" # 用户 ID,获取路径:登录DMXAPI → 工作台 → 个人设置
# 时间范围
# 可选值:"today"(今天)、"yesterday"(昨天)、"week"(最近7天)、"month"(最近30天)、"custom"(自定义)
QUERY_MODE = "today"
# 自定义时间范围(仅当 QUERY_MODE = "custom" 时生效)
# 格式:"YYYY-MM-DD" 或 "YYYY-MM-DD HH:MM:SS"
CUSTOM_START = "2025-01-01 00:00:00"
CUSTOM_END = "2025-01-01 23:59:59"
# 每页显示条数
PAGE_SIZE = 50
# 筛选条件(留空表示不筛选,查询全部)
TOKEN_NAME = "" # 按令牌名称筛选,例如 "我的令牌A"
MODEL_NAME = "" # 按模型名称筛选,例如 "gpt-5.4"、"claude-sonnet-4-20250514"
IP_FILTER = "" # 按 IP 地址筛选,例如 "192.168.1.1"
# ========================
# 以下为自动处理逻辑,无需修改
URL = "https://www.dmxapi.cn/api/log/self"
def get_log_detail(start_timestamp: int, end_timestamp: int, page: int = 1,
page_size: int = PAGE_SIZE, log_type: int = 0,
token_name: str = TOKEN_NAME, token_group: str = "",
model_name: str = MODEL_NAME, ip: str = IP_FILTER,
response_id: str = "", request_id: str = ""):
"""获取消耗明细日志数据"""
headers = {
"Accept": "application/json",
"Authorization": f"{SYSTEM_TOKEN}",
"Rix-Api-User": USER_ID,
}
params = {
"p": page,
"page_size": page_size,
"type": log_type,
"token_name": token_name,
"token_group": token_group,
"model_name": model_name,
"start_timestamp": start_timestamp,
"end_timestamp": end_timestamp,
"ip": ip,
"response_id": response_id,
"request_id": request_id
}
response = requests.get(URL, headers=headers, params=params)
if response.status_code != 200:
print(f"请求失败: {response.status_code}")
return {}
result = response.json()
if not result.get("success"):
print(f"接口返回错误: {result.get('message')}")
return {}
return result.get("data", {})
def get_all_logs(start_timestamp: int, end_timestamp: int, max_pages: int = 100):
"""
获取所有日志数据(分页获取)
Args:
start_timestamp: 开始时间戳
end_timestamp: 结束时间戳
max_pages: 最大获取页数
Returns:
list: 所有日志条目列表
"""
all_items = []
page = 1
while page <= max_pages:
data = get_log_detail(start_timestamp, end_timestamp, page=page)
if not data:
break
items = data.get("items", [])
if not items:
break
all_items.extend(items)
# 检查是否还有更多数据
total = data.get("total", 0)
if len(all_items) >= total:
break
page += 1
print(f"已获取 {len(all_items)}/{total} 条记录...")
return all_items
def print_log_detail(data: dict):
"""格式化输出日志明细"""
if not data:
print("没有数据")
return
items = data.get("items", [])
page = data.get("page", 1)
page_size = data.get("page_size", PAGE_SIZE)
total = data.get("total", 0)
print(f"分页信息: 第 {page} 页 | 每页 {page_size} 条 | 共 {total} 条记录")
print("-" * 120)
if not items:
print(" 暂无消耗记录")
return
print(f"{'序号':>4} {'模型名称':<25} {'消耗(元)':>10} {'输入Token':>10} {'输出Token':>10} {'耗时(ms)':>8} {'请求时间':<20}")
print("-" * 120)
for idx, item in enumerate(items, 1):
model = item.get('model_name', 'N/A')[:23]
quota = item.get('quota', 0) / 500000
prompt_tokens = item.get('prompt_tokens', 0)
completion_tokens = item.get('completion_tokens', 0)
use_time = item.get('use_time', 0)
created_at = item.get('created_at', 0)
time_str = datetime.fromtimestamp(created_at).strftime('%Y-%m-%d %H:%M:%S') if created_at else 'N/A'
print(f"{idx:>4} {model:<25} {quota:>10.6f} {prompt_tokens:>10} {completion_tokens:>10} {use_time:>8} {time_str:<20}")
def analyze_logs(items: list) -> dict:
"""
分析日志数据
Returns:
dict: 包含分析结果的字典
"""
if not items:
return {}
# 按模型分组统计
model_stats = {}
total_prompt_tokens = 0
total_completion_tokens = 0
for item in items:
model = item.get('model_name', 'unknown')
quota = item.get('quota', 0) / 500000
prompt_tokens = item.get('prompt_tokens', 0)
completion_tokens = item.get('completion_tokens', 0)
total_prompt_tokens += prompt_tokens
total_completion_tokens += completion_tokens
if model not in model_stats:
model_stats[model] = {
'total_quota': 0,
'count': 0,
'prompt_tokens': 0,
'completion_tokens': 0
}
model_stats[model]['total_quota'] += quota
model_stats[model]['count'] += 1
model_stats[model]['prompt_tokens'] += prompt_tokens
model_stats[model]['completion_tokens'] += completion_tokens
# 计算总消耗
total_consumption = sum(stats['total_quota'] for stats in model_stats.values())
# 按消耗排序
sorted_models = sorted(model_stats.items(), key=lambda x: x[1]['total_quota'], reverse=True)
return {
'total_consumption': total_consumption,
'model_count': len(model_stats),
'request_count': len(items),
'total_prompt_tokens': total_prompt_tokens,
'total_completion_tokens': total_completion_tokens,
'model_stats': dict(sorted_models)
}
def save_analysis_report(analysis: dict, items: list, start_time: datetime, end_time: datetime, filepath: str = "消耗细化报告.txt"):
"""
保存分析报告到文件
Args:
analysis: 分析结果
items: 原始数据
start_time: 开始时间
end_time: 结束时间
filepath: 保存路径
"""
import os
# 获取脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
full_path = os.path.join(script_dir, filepath)
with open(full_path, 'w', encoding='utf-8') as f:
f.write("=" * 70 + "\n")
f.write(" API 消耗细化分析报告\n")
f.write("=" * 70 + "\n\n")
f.write(f"报告生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"查询时间范围: {start_time.strftime('%Y-%m-%d %H:%M')} 至 {end_time.strftime('%Y-%m-%d %H:%M')}\n\n")
f.write("-" * 70 + "\n")
f.write("【总体统计】\n")
f.write("-" * 70 + "\n")
f.write(f" 总消耗额度: {analysis.get('total_consumption', 0):.4f}\n")
f.write(f" 使用模型数: {analysis.get('model_count', 0)}\n")
f.write(f" 请求总次数: {analysis.get('request_count', 0)}\n")
f.write(f" 总输入Token: {analysis.get('total_prompt_tokens', 0):,}\n")
f.write(f" 总输出Token: {analysis.get('total_completion_tokens', 0):,}\n\n")
f.write("-" * 70 + "\n")
f.write("【各模型消耗明细】\n")
f.write("-" * 70 + "\n")
model_stats = analysis.get('model_stats', {})
for i, (model, stats) in enumerate(model_stats.items(), 1):
percentage = (stats['total_quota'] / analysis['total_consumption'] * 100) if analysis['total_consumption'] > 0 else 0
f.write(f"\n {i}. {model}\n")
f.write(f" 消耗额度: {stats['total_quota']:.4f} ({percentage:.1f}%)\n")
f.write(f" 请求次数: {stats['count']}\n")
f.write(f" 输入Token: {stats['prompt_tokens']:,}\n")
f.write(f" 输出Token: {stats['completion_tokens']:,}\n")
f.write(f" 平均每次: {stats['total_quota'] / stats['count']:.6f}\n")
f.write("\n" + "-" * 70 + "\n")
f.write("【详细记录】\n")
f.write("-" * 70 + "\n")
f.write(f"{'序号':>4} {'模型名称':<25} {'额度':>10} {'输入':>8} {'输出':>8} {'时间':<20}\n")
f.write("-" * 70 + "\n")
for i, item in enumerate(items, 1):
model = item.get('model_name', 'N/A')[:23]
quota = item.get('quota', 0) / 500000
prompt = item.get('prompt_tokens', 0)
completion = item.get('completion_tokens', 0)
created_at = item.get('created_at', 0)
time_str = datetime.fromtimestamp(created_at).strftime('%Y-%m-%d %H:%M:%S') if created_at else 'N/A'
f.write(f"{i:>4} {model:<25} {quota:>10.6f} {prompt:>8} {completion:>8} {time_str:<20}\n")
f.write("\n" + "=" * 70 + "\n")
print(f"\n分析报告已保存至: {full_path}")
def get_time_range(mode: str) -> tuple:
"""
根据查询模式获取时间范围
Args:
mode: 查询模式 ("today", "yesterday", "week", "month", "custom")
Returns:
tuple: (start_timestamp, end_timestamp, start_time, end_time)
"""
from datetime import timedelta
now = datetime.now()
today = now.replace(hour=0, minute=0, second=0, microsecond=0)
if mode == "today":
start_time = today
end_time = today.replace(hour=23, minute=59, second=59)
elif mode == "yesterday":
start_time = today - timedelta(days=1)
end_time = start_time.replace(hour=23, minute=59, second=59)
elif mode == "week":
start_time = today - timedelta(days=6)
end_time = now
elif mode == "month":
start_time = today - timedelta(days=29)
end_time = now
elif mode == "custom":
try:
if len(CUSTOM_START) == 10:
start_time = datetime.strptime(CUSTOM_START, "%Y-%m-%d")
else:
start_time = datetime.strptime(CUSTOM_START, "%Y-%m-%d %H:%M:%S")
if len(CUSTOM_END) == 10:
end_time = datetime.strptime(CUSTOM_END, "%Y-%m-%d").replace(hour=23, minute=59, second=59)
else:
end_time = datetime.strptime(CUSTOM_END, "%Y-%m-%d %H:%M:%S")
except ValueError as e:
print(f"时间格式错误: {e}")
print("请使用格式: YYYY-MM-DD 或 YYYY-MM-DD HH:MM:SS")
exit(1)
else:
print(f"未知的查询模式: {mode}")
print("支持的模式: today, yesterday, week, month, custom")
exit(1)
return int(start_time.timestamp()), int(end_time.timestamp()), start_time, end_time
if __name__ == "__main__":
import time
# 根据配置获取时间范围
start_timestamp, end_timestamp, start_time, end_time = get_time_range(QUERY_MODE)
print(f"查询模式: {QUERY_MODE}")
print(f"查询时间范围: {start_time.strftime('%Y-%m-%d %H:%M:%S')} 至 {end_time.strftime('%Y-%m-%d %H:%M:%S')}")
print()
# 获取第一页数据预览
data = get_log_detail(start_timestamp, end_timestamp)
print_log_detail(data)
# 获取所有数据并分析
total = data.get("total", 0)
if total > 0:
print(f"\n正在获取全部 {total} 条记录...")
all_items = get_all_logs(start_timestamp, end_timestamp)
if all_items:
print("\n正在生成分析报告...")
analysis = analyze_logs(all_items)
print(f"\n【快速统计】")
print(f" 总消耗: {analysis['total_consumption']:.4f} 元")
print(f" 模型数: {analysis['model_count']}")
print(f" 请求数: {analysis['request_count']}")
print(f" 总输入Token: {analysis['total_prompt_tokens']:,}")
print(f" 总输出Token: {analysis['total_completion_tokens']:,}")
# 各模型消耗排行
print(f"\n【各模型消耗排行】")
model_stats = analysis.get('model_stats', {})
for i, (model, stats) in enumerate(model_stats.items(), 1):
percentage = (stats['total_quota'] / analysis['total_consumption'] * 100) if analysis['total_consumption'] > 0 else 0
print(f" {i}. {model}")
print(f" 消耗: {stats['total_quota']:.4f} 元 ({percentage:.1f}%) | 请求: {stats['count']} 次 | 输入: {stats['prompt_tokens']:,} | 输出: {stats['completion_tokens']:,}")
# 保存到文件
save_analysis_report(analysis, all_items, start_time, end_time)返回示例
json
查询模式: today
查询时间范围: 2026-03-26 00:00:00 至 2026-03-26 23:59:59
分页信息: 第 1 页 | 每页 50 条 | 共 346 条记录
------------------------------------------------------------------------------------------------------------------------
序号 模型名称 消耗(元) 输入Token 输出Token 耗时(ms) 请求时间
------------------------------------------------------------------------------------------------------------------------
1 claude-opus-4-6 3.176290 3 9 6 2026-03-26 15:03:47
2 claude-opus-4-6 0.153382 1 182 8 2026-03-26 15:03:03
3 claude-opus-4-6 0.438954 1 1335 32 2026-03-26 15:02:54
4 claude-sonnet-4-6 0.301516 1 58 3 2026-03-26 15:02:33
5 claude-sonnet-4-6 0.032740 1 88 3 2026-03-26 15:02:29
6 claude-sonnet-4-6 0.296932 3 92 10 2026-03-26 15:02:21
7 claude-opus-4-6 0.946908 1 219 57 2026-03-26 15:02:20
8 claude-opus-4-6 0.365540 1 284 66 2026-03-26 15:01:20
9 claude-opus-4-6-cc 2.408732 1 58 88 2026-03-26 15:01:15
10 claude-opus-4-6 0.271684 1 416 68 2026-03-26 15:00:11
11 claude-opus-4-6-cc 2.411176 3 144 60 2026-03-26 14:59:47
12 claude-opus-4-6 0.462750 3 206 25 2026-03-26 14:58:54
13 claude-opus-4-6-cc 0.308918 3 450 58 2026-03-26 14:58:34
14 claude-opus-4-6 0.301752 1 83 21 2026-03-26 14:57:27
15 claude-opus-4-6 0.306178 3 94 38 2026-03-26 14:57:06
16 claude-opus-4-6 3.595066 3 208 13 2026-03-26 14:54:53
17 claude-opus-4-6-cc 0.206170 1 154 7 2026-03-26 14:54:47
18 claude-opus-4-6-cc 0.227534 1 566 12 2026-03-26 14:54:40
19 claude-opus-4-6-cc 0.217624 1 323 14 2026-03-26 14:54:28
20 claude-opus-4-6-cc 0.205330 1 110 8 2026-03-26 14:54:13
21 claude-opus-4-6-cc 0.215576 1 110 15 2026-03-26 14:54:05
22 claude-opus-4-6-cc 2.304668 3 111 9 2026-03-26 14:53:49
23 claude-opus-4-6-cc 2.342270 3 967 72 2026-03-26 14:52:58
24 claude-opus-4-6-cc 0.010462 3 168 11 2026-03-26 14:51:45
25 claude-opus-4-6-cc 0.192330 1 40 22 2026-03-26 14:46:32
26 claude-opus-4-6-cc 2.274580 1 227 51 2026-03-26 14:46:09
27 claude-opus-4-6-cc 2.273518 3 294 14 2026-03-26 14:45:18
28 claude-opus-4-6-cc 0.213472 1 328 10 2026-03-26 14:37:39
29 claude-opus-4-6-cc 0.244946 1 305 6 2026-03-26 14:37:28
30 claude-opus-4-6-cc 0.195546 1 125 7 2026-03-26 14:37:22
31 claude-opus-4-6-cc 0.215616 1 479 13 2026-03-26 14:37:14
32 claude-opus-4-6-cc 0.218292 1 136 8 2026-03-26 14:37:01
33 claude-opus-4-6-cc 2.231842 1 358 10 2026-03-26 14:36:53
34 claude-opus-4-6-cc 2.256942 1 1037 21 2026-03-26 14:36:42
35 claude-opus-4-6-cc 0.193096 1 110 19 2026-03-26 14:36:21
36 claude-opus-4-6-cc 0.185164 3 111 7 2026-03-26 14:36:02
37 claude-opus-4-6-cc 2.180924 3 294 108 2026-03-26 14:34:06
38 claude-opus-4-6 3.162328 3 9 25 2026-03-26 14:34:06
39 claude-opus-4-6-cc 2.183204 3 489 25 2026-03-26 14:30:47
40 0.000000 0 0 0 2026-03-26 14:26:10
41 claude-opus-4-6-cc 2.157950 3 135 8 2026-03-26 14:25:44
42 claude-opus-4-6-cc 0.210678 3 408 12 2026-03-26 14:23:30
43 claude-opus-4-6-cc 0.225500 3 818 14 2026-03-26 14:21:28
44 claude-opus-4-6-cc 0.377056 3 279 12 2026-03-26 14:19:35
45 claude-opus-4-6-cc 2.160540 3 821 28 2026-03-26 14:18:37
46 claude-opus-4-6-cc 0.221724 3 1102 22 2026-03-26 14:17:12
47 claude-opus-4-6-cc 0.004690 3 75 8 2026-03-26 14:16:50
48 gpt-5.4 0.000000 0 0 75 2026-03-26 14:13:43
49 claude-opus-4-6-cc 1.950548 3 928 57 2026-03-26 14:13:13
50 claude-opus-4-6-cc 1.923774 3 715 34 2026-03-26 14:10:57
正在获取全部 346 条记录...
已获取 50/346 条记录...
已获取 100/346 条记录...
已获取 150/346 条记录...
已获取 200/346 条记录...
已获取 250/346 条记录...
已获取 300/346 条记录...
正在生成分析报告...
【快速统计】
总消耗: 224.1485 元
模型数: 8
请求数: 346
总输入Token: 641,115
总输出Token: 134,404
【各模型消耗排行】
1. claude-opus-4-6
消耗: 114.9335 元 (51.3%) | 请求: 139 次 | 输入: 227 | 输出: 35,910
2. claude-opus-4-6-cc
消耗: 103.6920 元 (46.3%) | 请求: 176 次 | 输入: 568,446 | 输出: 69,660
3. doubao-seedream-5.0-lite
消耗: 1.9800 元 (0.9%) | 请求: 5 次 | 输入: 5 | 输出: 19,800
4. gemini-2.5-flash-image-ssvip
消耗: 1.4438 元 (0.6%) | 请求: 9 次 | 输入: 4,175 | 输出: 6,551
5. claude-sonnet-4-6
消耗: 1.0768 元 (0.5%) | 请求: 9 次 | 输入: 13 | 输出: 920
6. gpt-5.4
消耗: 0.8564 元 (0.4%) | 请求: 6 次 | 输入: 68,230 | 输出: 47
7. gemini-3.1-flash-image-preview
消耗: 0.1660 元 (0.1%) | 请求: 1 次 | 输入: 19 | 输出: 1,516
8.
消耗: 0.0000 元 (0.0%) | 请求: 1 次 | 输入: 0 | 输出: 0
分析报告已保存至: c:\Users\a1\Desktop\测试保存代码\消耗细化报告.txt© 2025 DMXAPI 消耗细化 日志查询 🍌